
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 글또
- 데이터디스커버리플랫폼
- 인과추론
- 성장
- data
- 분석한스푼
- aha-moment
- 프롬프트
- n8n
- EDA
- 전환분석
- 주가데이터
- 신기효과
- PyGWalker
- gapminder
- 시각화
- pandasai
- 트위먼의법칙
- DataAnalyst
- retentioneering
- 야구
- 프롬프트엔지니어링
- productanalysis
- 데이터분석
- data-analysis
- DataAnalysis
- 아하모먼트
- 데이터
- 벅슨의역설
- 데이터분석가
데이터 생존 로그
⚖️ 성향 점수 매칭(PSM): 동등하지 않은 비교는 비교가 아니다! 본문
데이터를 해석하고 분석할 때, 가장 주의해야 하는 것이 편향이다.
대부분의 데이터는 편향을 담고 있고, 이를 기반으로 단순 집계한 통계량에도 편향이 섞여있을 수 밖에 없다.
한 가지 예시를 들어보자!

우리가 인스타그램의 데이터 분석가라고 가정해 보자.
그리고 다음과 같은 분석 결과를 보게 되었다.
릴스를 1회라도 올린 유저가 그렇지 않은 유저에 비해 팔로워 수가 더 많다.(통계적 유의)
따라서 '릴스 업로드 유무'는 '팔로워 수'의 요인이라고 볼 수 있다.
우리는 위 분석 결과를 '통계적으로 유의'하기 때문에 받아들여야 할까?
당연히 아니다.
애초에 릴스를 1회라도 올린 유저는 다른 활동 역시 활발하게 할 확률이 높고(게시글, 댓글, 좋아요 등),
이에 따라 팔로워 수가 높을 수도 있기 때문이다.
즉, '팔로워 수'라는 결과 변수에 대한 '릴스 업로드 유무'라는 처치 변수의 순수한 영향력을 측정하는 데,
'게시글 수', '댓글 수', '좋아요 수' 등과 같은 공변량이 편향을 발생시켜, 집계의 평등성을 해치고 있는 것이다.
그렇다면 우리는 어떻게 '릴스 업로드 유무'만의 '팔로워 수'에 대한 영향력을 측정해 볼 수 있을까?
첫 번째 방법으로는 '실험'이 있겠다.
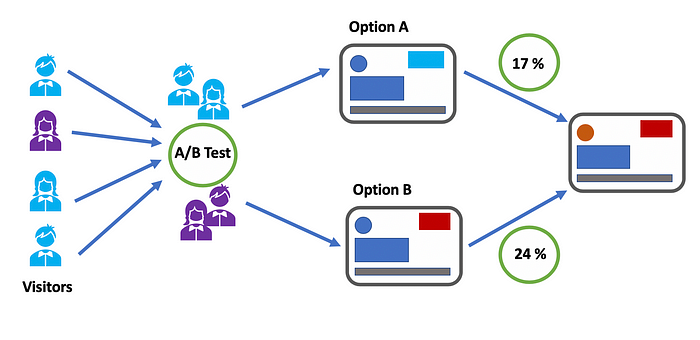
현실적으로 인스타그램에서 모든 유저에게 무작위로 ‘릴스 기능’을 할당하기는 쉽지 않겠지만, 가장 확실한 방법은 무작위 배정(Random Assignment)을 통한 실험이다.
예를 들어, 인스타그램 운영팀에서 신규 크리에이터 일부 집단에게만 릴스 업로드를 장려(프로모션)하여 그 차이를 비교하는 방식을 활용할 수도 있겠다.
이렇게 무작위로 처치를 부여하면, ‘릴스를 올릴 가능성이 높을 만한 유저’라는 사전 특성이 무작위로 분산되므로, 결과(팔로워 수)에 대한 인과적 해석이 한결 수월해진다.
만일 실험이 어려운 상황이라면 '성향 점수 매칭(Propensity Score Matching)'이라는 통계 모델에 의한 공변량 보정 등의 방법을 사용할 수 있다.

성향 점수 매칭은 '처치 여부에 영향을 줄 수 있는 요인이 비슷한 두 집단을 만들고, 결과 변수에 대해 동등한 비교를 하는 것'이 기본 아이디어이다.
인스타그램 예시로 돌아가보자.
예시에서 가장 문제였던 점은 '게시글', '댓글', '좋아요' 등의 요인에 따라 릴스를 업로드 할 확률이 달라지고, 이에 따라 '팔로워 수'에 대한 동등한 비교가 어렵다는 점이었다.
그러면 위 문제를 해결하기 위해 다음과 같이 진행해 보자.
- '게시글', '댓글', '좋아요' 등의 요인에 따른 '릴스 업로드 확률'을 예측
- 실제로 릴스를 업로드 한 집단과, 릴스를 업로드 하지 않은 집단에서 릴스 업로드 확률이 가장 유사한 한 쌍을 뽑기
- 바로 위 과정을 여러 번 반복하기
위 과정의 결과는 어떻게 될까?
데이터에 따라 다르겠지만, 우리가 PSM을 통해 얻고 싶은 이상적 결과는 다음과 같을 것이다.

Y축 각 항목은 공변량이고, X축은 SMD(표준화된 평균 차)이다.
즉, 각 공변량별로 PSM 이전(Unadjusted)와 이후(Adjusted)에 대하여 두 집단(릴스 업로드 유무)의 공변량별 차이를 볼 수 있는 플롯이다.
(위 플롯은 우리의 예시인 인스타그램 예시와 다른 플롯이다!! 참고 용도로만 볼 것!)
플롯을 보면, PSM 이전에는 두 집단 간의 공변량 차이가 컸다. (두 집단 간의 공변량의 차이(편향)이 존재했다.)
하지만 PSM을 한 후, 두 집단 간의 공변량의 차이가 거의 없어졌다.
위와 같이 이상적인 PSM 결과를 찾아낸다면, 우리는 이제 두 집단 간의 동등한 비교를 할 수 있게 된다!!
PSM을 통해 잘 매칭된 처리 집단(릴스 업로드)과 통제 집단(릴스 미업로드)을 확보한 뒤에는, 두 집단 간 팔로워 수의 차이를 상대적으로 편향이 줄어든 상태에서 비교할 수 있다.
이 과정을 거치면 단순히 “릴스 한 번이라도 올린 사람은 팔로워가 더 많더라”라는 결론이 아니라,
“비슷한 활동량·성향을 가진 계정을 비교했을 때, 릴스 업로드가 팔로워 수에 미치는 영향”을 좀 더 명확히 추정하게 된다.
결과적으로, 인과추론의 주요 원리는 “가능한 한 처리 그룹과 통제 그룹이 유사해야 한다”는 데 있다.
실험에서는 무작위 배정을 통해 사전 특성을 자동으로 분산시키지만, 관측 데이터 기반 분석에서는 PSM 등의 기법으로 이러한 유사성을 최대한 확보하려 노력해야 한다.
물론 매칭 이후에도 측정되지 않은 잠재 요인(콘텐츠의 질, 운영자의 개인 역량 등)이 남아있을 수 있으므로, 결과 해석에는 주의가 필요하다.
이처럼 인과추론 관점에서 데이터를 바라보면, 단순 통계량을 넘어 “무엇이 진짜 ‘원인’이 되어 결과에 영향을 미치는가?”라는 질문에 한 걸음 더 다가갈 수 있겠다!
'통계💡' 카테고리의 다른 글
| 🌟 데이터 분석가가 회귀 분석으로 할 수 있는 4가지② - 변수 선택과 비선형 패턴 찾기 (0) | 2024.12.22 |
|---|---|
| 🌟 데이터 분석가가 회귀 분석으로 할 수 있는 4가지① - 예측과 요인 분석 (0) | 2024.11.24 |
| 데이터 분석가라면 반드시 알아야할 데이터의 함정 세 가지! (0) | 2024.03.31 |
| 0. 벅슨의 역설: 가짜 상관성에 속아선 안돼! (0) | 2023.11.08 |



